[성능 테스트] Artillery로 부하 테스트 하기(1/3), Artillery 설치
현재 진행하고 있는 뉴스피드 프로젝트의 기능들을 얼추 마무리하고 나서, 문득 내가 구현한 한 api에 대한 성능을 평가해보고 확장성을 검증해보기 위해 부하 테스트를 진행해 보기로 했다. 개
developer-jinnie.tistory.com
지난 글에서는 부하 테스트를 위한 툴을 정하고 간단한 테스트를 진행해 봤다.
이번 글에서는 특정 API에 대해 부하 테스트를 진행한 후 결과를 분석해보는 시간을 가져보려 한다.
게시글 기능이 유저, 댓글, 게시글 좋아요, 멀티미디어 등 여러 엔티티와 연관관계로 묶여있는데다가 피드 서비스의 핵심 기능이기 때문에 게시글 전체 목록을 보여주는 '게시글 전체보기 API'를 선택해서 부하를 주어 보기로 했다.
테스트 환경
유저 1000명, 게시글 1000개 정도를 더미 데이터로 넣어서 테스트 해보기로 했고, 더미 데이터를 실제 DB가 아니라 테스트용 DB를 만들어 더미데이터를 삽입한 후 테스트했다. 또한 서버는 로컬 서버로 지정했다.
더미 데이터를 만드는 방법은 여러가지가 있지만 나는 조금 더 개발자 답게(?) 파이썬으로 csv 파일을 만든 뒤 DB에 bulk insert 하는 방법으로 생성했다.
+ 더미 데이터 만들기
파이썬으로 간단한 스크립트를 작성해서 실행 시 부하 테스트에 사용할 csv 파일이 빠르게 생성되도록 해줬다.
import csv
with open('users.csv', 'w', newline='') as file:
writer = csv.writer(file)
writer.writerow(["username", "password"])
for i in range(1, 1001):
writer.writerow([f"user{i}", f"password{i}"])
이후 인텔리제이 DB 콘솔로 테스트용 DB를 만든 다음, 테스트용 DB 스키마 밑에 삽입해 줄 users 테이블을 만들어준다. 그 후 executemany 메소드를 사용해서 한 번에 데이터베이스에 삽입해주자!
import csv
import mysql.connector
# MySQL connection
cnx = mysql.connector.connect(user='root', password='비밀번호', host='localhost', database='데이터베이스이름')
cursor = cnx.cursor()
# Read CSV file
with open('users.csv') as f:
reader = csv.reader(f)
next(reader) # Skip the header row
data = [(row[0], row[1]) for row in reader]
# Bulk insert data
stmt = "INSERT INTO users (username, password) VALUES (%s, %s)"
cursor.executemany(stmt, data) # executemany 메소드를 사용해 한 번에 데이터베이스에 삽입
# Commit changes and close
cnx.commit()
cursor.close()
cnx.close()
게시글 더미 데이터도 똑같은 방식으로 넣어 주자.
import csv
from datetime import datetime
# CSV 파일 생성
with open('boards.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(["id", "title", "content", "created_at", "modified_at", "user_id", "username"])
for i in range(1, 1001):
# 현재 시각을 문자열로 변환
now = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
# 각 행에 데이터 추가
writer.writerow([i, f"유기묘 발견했습니다", "유기묘 구출 작전", now, now, 1, "user1"])(인코딩 방식을 미리 utf-8로 지정해 줘야 csv 파일이 안깨진다) 유저 데이터와 동일한 방식으로 삽입 해주면, 게시글 더미 데이터도 삽입 완료다.

+ 참고: 더미 데이터는 이 사이트를 통해서도 만들 수 있다. (https://www.mockaroo.com/)
1차 테스트

지난번 포스팅에서 테스트했던 test-config.yml 파일을 수정해줬다. 로컬에서 진행하기 위해서 URL은 그대로 로컬 서버로 지정해줬고, 테스트 구성은 아래와 같다.
- Warm up: 웜업 단계. 30초 동안 매초 10개 요청
- Ramp up load: 20초 동안 매초 20개의 요청에서 시작 👉 200개의 요청으로 늘림
- Sustained load: 20초 동안 200개의 요청을 일정한 속도로 유지해서 지속적으로 고부하에 견딜 수 있는지를 테스트
- End of load: 부하를 마무리하는 단계. 30초 동안 매초 200개의 요청에서 시작 👉 20개의 요청으로 줄임
약 1만 개의 call을 목표로 진행하였으며 결과는 아래와 같다.

난리 났다. ㅎ
Artillery를 통해 쏜 거의 대부분의 요청이 errors.ETIMEDOUT 와 함께 실패했다.
찾아보니 이것은 artillery가 하나의 요청에 대해서 기다려주는 시간 제한인데, 이 시간이 지나면 아틸러리는 요청을 실패처리하고 더 이상 응답을 기다리지 않는다고 한다. 따라서 타임아웃 시간을 늘릴 필요가 있었다.
타임아웃 설정

상단의 yml 파일에 타임아웃을 늘려주는 코드를 추가해서 다시 테스트를 돌려줬다.
1-2차 테스트

1차 테스트보단 많이 줄었지만, 타임아웃 설정을 해 줬음에도 불구하고 계속 errors.ETIMEDOUT 으로 요청이 실패했다.. 타임아웃 시간을 더 늘려주기 보단 다른 요인이 있을 것 같아서 찾아봐야겠다고 생각했다.
구글링 해 보니, 부하 테스트 전 로깅으로 인한 성능 저하를 막기 위해 SQL 로깅 기능을 끄고 했다는 글을 보고 아 로그로 인한 성능 저하 생각을 못 했구나 .. 라는 생각이 들었다. 이런!
SQL 로깅 기능을 끄고 스프링 부트 logback 로그 레벨 설정을 해줬다.
<application.properties>
spring.jpa.properties.hibernate.show_sql=false
# Logging
logging.level.root=warn
다시 테스트 실행!
1-3차 테스트

총 9800개의 요청이 실패 없이 모두 응답 성공했다.
하지만 단순히 얼마나 많은 요청이 응답에 성공했느냐와 같은 절대적인 수치만 보면 안된다. 이건 컴퓨터 사양이나 현재 실행 중인 프로그램이 얼마나 되는지 등등에 따라 달라질 수 있는 문제라, 상대적인 수치가 얼마나 차이나는지를 봐야 한다.
테스트 결과를 통계로 한눈에 보기 위해 html로 빼줬다.
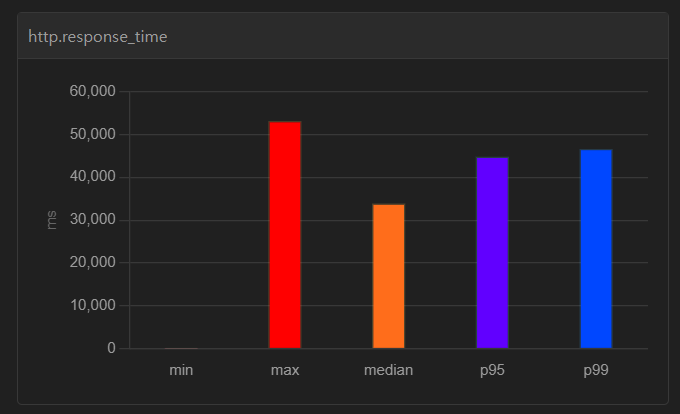
http.response_time에서 median - p95 - p99 간의 차이를 유의미하게 봐야 하는데, 중앙값과 p95 값에 큰 격차가 없어야 성능이 좋다고 볼 수 있다.
두 값의 차이가 많이 나지 않는 경우는 데이터의 대부분이 중앙값 주변에 집중되어 있고, 데이터가 균일하게 분포되어 있다는 것을 의미한다. 반대로 차이가 많이 날 수록 데이터가 비대칭적으로 분포되어 있다고 볼 수 있는 것이다.
즉, API 콜에 점진적으로 부하를 줘도 응답 속도의 중간값과 95 백분위 값의 격차가 적어야 높은 성능을 내는 코드라고 볼 수 있다.
상단의 그래프만 봐서는.. median(중앙값)과 p95(95 백분위) 값의 차이가 상당히 나는 것 같다..ㅎ
실제로 테스트 할 때는 보통 10만 건 정도를 기준으로 잡고 한다고 해서, 10만 건 정도를 하기 전에 약 1만 건으로 1차 부하 테스트를 진행해본 거였다. 하지만 이미 결과에서 중간값과 95 백분위 사이의 차이가 커서 1차 테스트에선 어떻게 하면 이 두 값의 차이를 줄일 수 있을 지에 초점을 두고 코드 리팩토링을 해보고자 했다.
성능 저하의 원인 찾기
이제 관련 코드를 뜯어보자.
게시글 전체 목록을 받아오기 위해서는 '게시글', '유저', '멀티미디어', '게시글 좋아요' 총 4가지 테이블에서 데이터를 조회한다.

Board 엔티티 필드를 살펴보면, 게시글은 유저와 N:1 관계를 맺고 있고,
멀티미디어, 댓글, 게시글 좋아요와는 1:N 관계를 맺고 있다.
더미데이터 넣기 전 기존의 DB로 게시글 목록 조회를 해보니 게시글 14개 유저 6명이였는데 sql 로그를 찍어보니 페이징 처리 이후 목록 조회 시 첫 페이지 10개의 게시물을 받아오기 위해 총 25번이나 조회가 이루어지고 있었다.
👉 게시글 목록 조회 2, 유저 조회 2, count 1, 멀티미디어 10 번 발생
요 놈이 성능 저하의 주범이로구만 .. 말로만 듣던 JPA의 N + 1 문제인 듯 했다.
N + 1 문제란?
특정 객체를 대상으로 수행한 쿼리가 해당 객체가 가지고 있는 연관관계 또한 조회하게 되면서 N번의 추가적인 쿼리가 발생하며 성능 저하를 유발하는 문제를 말한다. 즉, 1번의 쿼리를 날렸을 때 의도하지 않은 N번의 쿼리가 추가적으로 실행되는 것이다.
대표적인 해결 방법으론 아래 방법들이 있다.
- fetch join 사용
- @BatchSize 사용해서 일대다 관계를 배치로 변경
- @EntityGraph 사용해서 엔티티 그래프를 로드할 때 필요한 연관 엔티티를 함께 로드
- 세컨드 레벨 캐시 사용하여 두 번째 부터는 같은 데이터를 캐시에서 가져옴
방법들마다 적용해 보고, 비교해서 2차 테스트까지 한 결과를 다음 포스팅에 작성 해 봐야겠다.
<다음 글>
[성능 테스트][트러블슈팅] Artillery로 부하 테스트 하기(3/3), 성능 개선을 해보자
[성능 테스트][트러블 슈팅] Artillery로 부하 테스트 하기(2/3), 성능 저하 원인을 찾아보자[성능 테스트] Artillery로 부하 테스트 하기(1/3), Artillery 설치현재 진행하고 있는 뉴스피드 프로젝트의 기능
developer-jinnie.tistory.com
References
https://junbyeol.tistory.com/2
https://goddaehee.tistory.com/206
'Project > Newsfeed' 카테고리의 다른 글
| [프로젝트] Service, ServiceImpl 구조에 대한 내 생각과 결론 (부제: 이유없는 리팩토링을 지양하자) (6) | 2024.04.19 |
|---|---|
| [성능 테스트][트러블슈팅] Artillery로 부하 테스트 하기(3/3), 성능 개선을 해보자 (0) | 2024.04.15 |
| [프로젝트] 스택오버플로우 에러 해결 (부제: 드디어 내게도 말로만 듣던 이 에러가) (5) | 2024.04.13 |
| [프로젝트] AOP로 'API 수행 시간/회원 별 총 API 사용시간 누적 저장' 기능 다르게 구현하기와 그에 따른 고민 (1) | 2024.04.10 |
| [프로젝트] QueryDSL 사용 시 Q클래스 import 불가 문제 해결 (gradle) (2) | 2024.03.02 |